In this article, we will take a look at one of the most intriguing concepts which exist in our computer programming world – Spooling.
The word ‘SPOOL’ is derived from the old french word ‘espule’ which means a cylindrical container used to store information or data. Similar is the concept of spooling which is used in our Operating Systems.
To understand this concept thoroughly, we will first take a look at the basic operations that take place in our operating systems and subsequently, derive how the mechanism of spooling gives an edge to these operations.
So, the basic three functions that take place in our operating system are input, process, and output.
The system takes input from the user through the keyboard, mouse, or any other device, sends these instructions to the brain, i.e., CPU, where it is processed, and then returns the output on the screen. Now, if you observe that while taking inputs from the user, the CPU is not playing any role in the process and is in a null state (a state when it has no work to do), and also after the data is processed, it is again in a null state, until the result is displayed on the screen.
We observe that with such a scenario, it takes a lot of time to execute a single operation as the CPU is in a null state most of the time, and only performs its operations for a specific period. Why is the CPU even called the brain of the computer if we can’t use it to its fullest extent? To resolve this issue, the concept of Spooling comes into play.
Spooling in Operating System
The word ‘SPOOL’ stands for Simultaneous Peripheral Operations On-Line. It is a temporary storage space where the instructions are stored in the computer memory until the main memory takes up these instructions for processing. Through the process of spooling, we can get rid of the null state of the CPU. Spooling is the mechanism in which the system can take a number of instructions simultaneously using peripheral devices and store them in a secondary storage space or disk for further processing of data.
Let us understand this through a graphical representation:
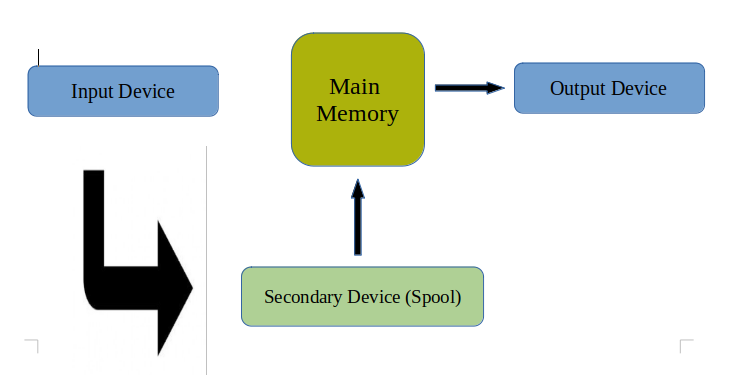
From the above representation, we can conclude that the data from the input device goes to a type of secondary storage space where it gets stored and then the main memory fetches this data one by one and executes the instructions without any delay. In this way, the CPU will be put to work most of the time and it will save time too. Most of the devices use this space while sending instructions in bulk, which reduces execution time and makes our interaction with the operating system smooth.
The post Spooling in Operating System appeared first on The Crazy Programmer.
from The Crazy Programmer https://ift.tt/3op1gxj
Comments
Post a Comment