In this article we will look into an interesting topic related to Linked List: Header Linked List. We will look at its description and types and will also look at the implementation and advantages of using it.
Header Linked List is a modified version of Singly Linked List. In Header linked list, we have a special node, the Header Node present at the beginning of the linked list. The Header Node is an extra node at the front of the list storing meaningful information about the list. Such a node is not similar in structure to the other nodes in the list. It does not represent any items of the list like other nodes rather than the information present in the Header node is global for all nodes such as Count of Nodes in a List, Maximum among all Items, Minimum value among all Items etc. This gives useful information about the Linked list.
Now, Header Linked List is of two types:
- Grounded Header Linked List
- Circular Header Linked List.
Grounded Header Linked List
In this type of Header Linked List, the last node of the list points to NULL or holds the reference to NULL Pointer. The head pointer points to the Header node of the list. If the there is no node to the next of head pointer or head.next equals NULL then we know that the Linked List is empty. The operations performed on the Header Linked List are same as Singly Linked List such as Insertion, Deletion, and Traversal of nodes. Let us understand this with an example:
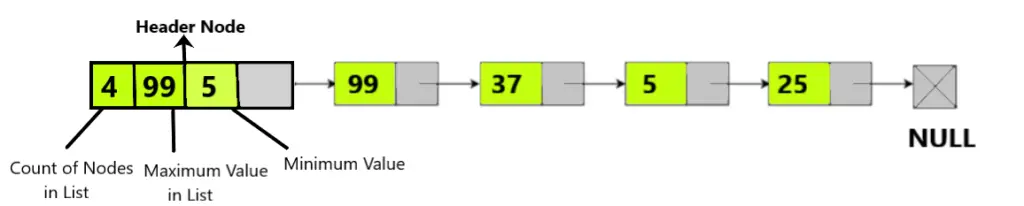
The above image shows a Grounded Header Linked List. We can see the Header Node at the beginning followed by the actual nodes of the list where the last node points to NULL. The header node maintains global information about the list. Firstly, we have to create Header Node first whose data field will be NULL or 0 initially. After that we can perform any operations on that linked list and store the global information about the linked list on the header node. Here, we store the count or Total no. of nodes present in the Linked List, the Maximum and Minimum value among all nodes in the list. So, in the above Linked List Total Nodes are 4 , Maximum Value is 99 and Minimum value is 5 which are present as fields in Header Node.
Circular Header Linked List
A Linked List whose last node points back to the First node or the Head Node of the list is called a Circular Linked List. Similarly, if the last node of the Header Linked List points back to Header Node then it is a Circular Header Linked List. The last node of the list does not hold NULL reference. In this case, We have to use external pointers to maintain the last node. The end of the list is not known while traversing. It can perform same operations as its counterpart such as Insert, Delete and Search. Let us see an example.
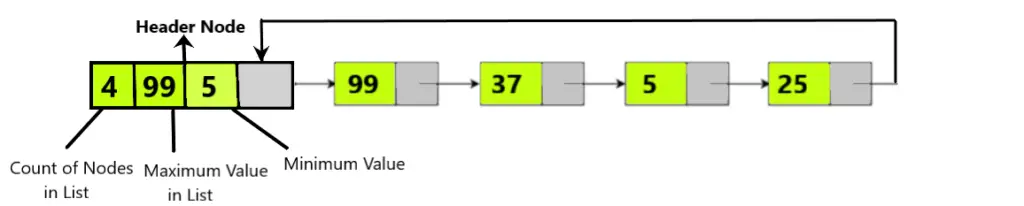
We can see the last node of the list points to the header node and not the node 99. There might be problem in traversing through the nodes. It is because the structure of the last node and header node are different which might cause an Type Mismatch Exception. So while traversing we fix the Header node and keep on traversing until node.next points to header node. The rest features of the Header remains same as its Grounded counterpart.
Implementation in Java
- For implementation, we will use a separate class for Header Node and normal Nodes which contain data respectively. We implement the Grounded Header Linked List since it is similar to the Circular Header Linked List in type of operations. We need to maintain some extra pointers in Circular variant during insertion and deletion.
- So, We will create a Header Node then add nodes subsequently to the list. For simplicity, we add nodes to the end of the list. We maintain a pointer to last node for adding nodes. On adding nodes we check if the current node’s data is greater than maximum of header node and update the max of head accordingly. We do the same for updating min value. At the end we also increment count of nodes in the Header Node.
- We will also perform delete operation. To keep the logic simple we delete nodes from end of the list and update the max and min accordingly before deleting the node from the list. After deletion, we also update the count of nodes. The we print the contents of the list. So let us look at the code.
class Node
{
int data;
Node next;
Node(int data)
{
this.data = data;
next = null;
}
}
// Header Node Class
class Header_Node
{
int count; // count of nodes.
int max; // max value among all nodes.
int min; // min value among all nodes.
Node next; // reference to beginning of the actual list.
Header_Node()
{
count = 0;
max = Integer.MIN_VALUE;
min = Integer.MAX_VALUE;
next = null;
}
}
public class HeaderLinkedList
{
static Node last; // maintains Last node of the list.
// print the linked list elements
static void printList(Header_Node head)
{
Node curr = head.next;
// We print header node separately.
System.out.print("["+head.count+" "+head.max+" "+head.min+"] -> ");
// then traverse and print actual nodes.
while (curr != null)
{
if(curr.next!=null)
System.out.print(curr.data + " -> ");
else
System.out.print(curr.data);
curr = curr.next;
}
System.out.println();
}
//add nodes to end of the list.
static void addNode(Header_Node head,Node node)
{
// if there are no nodes and only header node is present.
if(head.next==null)
{
head.next = node;
last = node;
}
// Otherwise add it to the end.
else
{
last.next = node;
last = node;
}
// Update max and min of list accordingly.
if(head.max < node.data)
{
head.max = node.data;
}
if(head.min > node.data)
{
head.min = node.data;
}
// Increment count of nodes.
head.count = head.count+1;
}
// Deletes node from end of the list.
static void deleteFromEnd(Header_Node head)
{
// if node to delete is min value node
// We need to update the 2nd minimum to header node then delete it.
if(last.data == head.min)
{
int new_min = Integer.MAX_VALUE;
Node start = head.next;
while(start.next.next!=null)
{
start = start.next;
new_min = Math.min(new_min,start.data);
}
// Print Node to Delete.
System.out.println("Node deleted is: "+start.next.data);
//Updating head min.
head.min = new_min;
start.next = null;
last = start;
}
// if node to delete is max value node
// We need to update the 2nd maximum to header node then delete it.
else if(last.data == head.max)
{
int new_max = Integer.MIN_VALUE;
Node start = head.next;
while(start.next.next!=null)
{
start = start.next;
new_max = Math.max(new_max,start.data);
}
// Print Node to Delete.
System.out.println("Node deleted is: "+start.next.data);
//Updating head max
head.min = new_max;
start.next = null;
last = start;
}
// Otherwise we do normal deletion.
else
{
Header_Node current = head;
Node start = current.next;
while(start.next.next!=null)
{
start=start.next;
}
// Print Node to Delete.
System.out.println("Node deleted is: "+start.next.data);
start.next = null;
last = start;
}
// decrement count of nodes in header node.
head.count = head.count-1;
}
// Driver Code to Test Above Methods.
public static void main(String[] args)
{
// Creating the Header Node.
Header_Node head = new Header_Node();
// Adding the nodes to end of list.
addNode(head,new Node(99));
addNode(head,new Node(37));
addNode(head,new Node(5));
addNode(head,new Node(25));
System.out.print("The Nodes in Linked List : ");
printList(head);
// Printing Contents of Head Node.
System.out.println("Total Nodes in Linked List: "+head.count);
System.out.println("Maximum Item in List: "+head.max);
System.out.println("Minimum Item in List: "+head.min);
System.out.println();
// Deleting node from end of list.
deleteFromEnd(head);
System.out.println();
System.out.print("The Nodes in Linked List : ");
printList(head);
System.out.println("Total Nodes in Linked List: "+head.count);
System.out.println("Maximum Item in List: "+head.max);
System.out.println("Minimum Item in List: "+head.min);
System.out.println();
deleteFromEnd(head);
System.out.println();
System.out.print("The Nodes in Linked List : ");
printList(head);
System.out.println("Total Nodes in Linked List: "+head.count);
System.out.println("Maximum Item in List: "+head.max);
System.out.println("Minimum Item in List: "+head.min);
System.out.println();
}
}
Output:
The Nodes in Linked List : [4 99 5] -> 99 -> 37 -> 5 -> 25 Total Nodes in Linked List: 4 Maximum Item in List: 99 Minimum Item in List: 5 Node deleted is: 25 The Nodes in Linked List : [3 99 5] -> 99 -> 37 -> 5 Total Nodes in Linked List: 3 Maximum Item in List: 99 Minimum Item in List: 5 Node deleted is: 5 The Nodes in Linked List : [2 99 37] -> 99 -> 37 Total Nodes in Linked List: 2 Maximum Item in List: 99 Minimum Item in List: 37
Advantages of Header Linked List
- In the header node of the linked list we store the total nodes in the List, so we can easily get the count of nodes in O(1) time without the need to traverse the list. As the size of the list is stored in Header itself.
- Another upper hand we have is that while inserting a new node in the linked list we don’t need to check whether start or head node is null or not because the header node will always exist and we can insert a new node just after that.
- Insertion and deletion of nodes become easier as there is no overhead of checking whether the head is NULL.
- If we are given a list of data items and we need to search for the maximum and minimum value among them we can get them easily using the header node. If we want we can maintain any number of data items in the header node.
- Another application of header linked lists lies in maintaining the polynomials in memory, where the header node can represent Zero degree Polynomial.
So that’s it for the article, you can try out the code shown above with different examples and execute them in your Java IDE or Compiler to get a clear idea. Feel free to leave your suggestions/doubts in the comment section below.
The post Header Linked List in Data Structure appeared first on The Crazy Programmer.
from The Crazy Programmer https://ift.tt/3ewgiyh
Comments
Post a Comment